本文介绍实验室团队在CVPR 2025上发表的一项工作,该工作旨在提升可泛化神经辐射场(NeRF)的渲染效率。
论文标题:Depth-Guided Bundle Sampling for Efficient Generalizable Neural Radiance Field Reconstruction
当前面临的挑战与研究动机
神经辐射场 (NeRF) 在新视角合成方面取得了显著的成果。然而,将NeRF泛化至新场景时,现有方法通常面临计算成本较高的问题,这主要是由于渲染过程中需要对每条光线进行密集采样。此外,与针对特定场景优化的NeRF不同,可泛化模型通常难以充分利用场景的先验信息进行加速。
这些因素限制了可泛化NeRF在需要较高实时性的场景中的应用。因此,本研究旨在探索一种能够提高渲染效率,同时努力维持或提升重建质量的方法。
我们提出的方法概述
我们注意到自然场景通常具有分块平滑的特性,这意味着在许多区域进行统一的密集采样可能存在冗余。基于此观察,我们提出了一种名为“深度引导的束采样 (Depth-Guided Bundle Sampling)”的策略。
该策略主要包含两个方面:
束采样 (Bundle Sampling):我们将目标视图中空间上相邻的一组光线(例如2x2或4x4像素对应的光线)组织成一个“束” (Bundle)。然后,我们对这个“束”进行集体的采样和特征提取,旨在减少对多条光线进行独立处理所带来的计算冗余。我们将每个“束”建模为一个从相机中心发出的圆锥,并在该圆锥内部采样一系列内切球体作为采样单元。
深度引导的自适应采样 (Depth-Guided Adaptive Sampling):在“束采样”的基础上,我们利用预测的场景深度信息来指导采样点的分配。具体而言,该方法会根据深度的置信度,在场景中几何结构较为复杂、深度变化较大的区域(如物体边缘)分配相对更多的采样点,而在较为平滑的区域则适当减少采样点。我们希望通过这种方式,能在保证重要细节重建的同时,减少总体的采样数量。
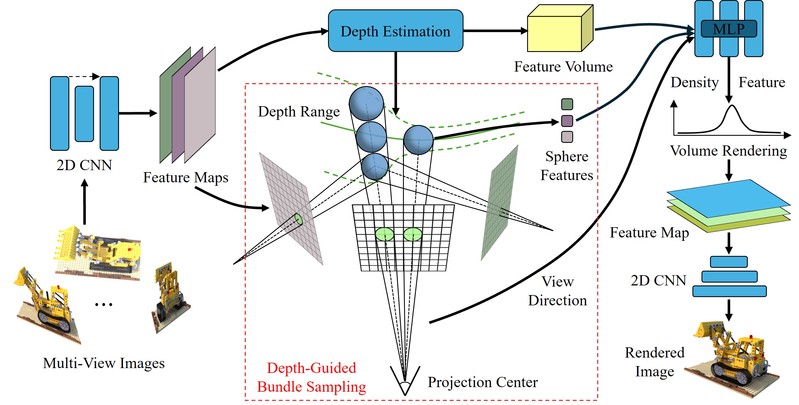
图1 将深度引导束采样策略用于ENeRF的网络架构
主要工作与实验发现
提出了一种束采样策略,通过对相邻光线束进行联合采样,以期减少采样数量并改善渲染速度和质量。
引入了一种深度引导的自适应采样方法,该方法根据局部深度范围动态调整采样点数,实验结果显示这有助于提升渲染速度,在保持图像质量的同时,FPS有约50%的提升。
在可泛化NeRF模型 (ENeRF) 和3D高斯溅射方法 (MVSGaussian) 上验证了该方法的适用性。
实验结果表明,与一些现有的可泛化NeRF方法相比,应用了我们策略的模型在渲染质量和速度方面取得了一定的改进。例如,在DTU数据集上,ENeRF+Ours (2x2) 相比原始ENeRF,在3视角设置下PSNR提升了1.27 dB,FPS提升了47%。ENeRF+Ours (4x4) 的渲染速度达到了原始ENeRF的两倍以上。
该方法允许用户通过调整束的大小等参数,在渲染质量和效率之间进行一定的权衡。
我们将提出的方法整合到现有的可泛化NeRF框架中,并在公开数据集上进行了实验评估。主要工作和发现如下:
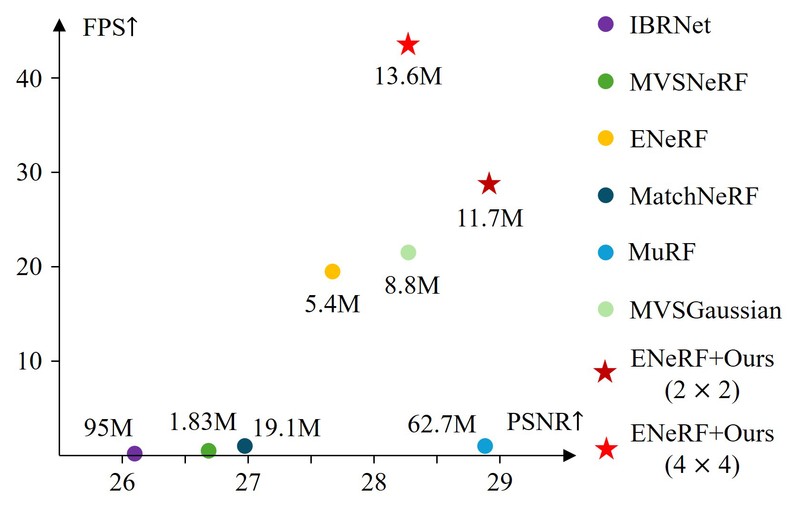
图2 DTU数据集上不同方法的渲染质量 (PSNR) 与速度 (FPS)。
技术方案简述
为实现上述目标,我们的方法包含以下几个主要技术环节:
球形采样与特征编码:对于每个“束”中的采样球体,我们将其投影到各个源视图中。根据其投影区域的大小,从源视图特征图的对应Mipmap层级中提取特征。这种方式旨在使特征能够反映采样区域的覆盖范围。
特征表示:为了平衡计算效率和细节保留,我们为每个采样球体编码了两种特征:一种是覆盖整个束区域的“联合束表示” (Joint Bundle Representation),另一种是针对束内各条原始光线提取的“射线专属表示” (Ray-Specific Representation),后者旨在捕捉高频细节。
自适应样本数分配:每个束沿其中心轴的采样点数量并非固定,而是根据预测的深度范围和预设的最小样本间距动态计算得出。
特征解码与图像合成:经过体渲染聚合后的联合束特征和射线专属特征,分别通过不同的网络模块解码,生成一个基础图像和一个细节增强层,两者叠加得到最终的渲染结果。
实验结果与分析
我们在包括DTU, Real Forward-facing和NeRF Synthetic在内的多个公开数据集上对方法进行了评估。
| 方法 | 3视角 | 2视角 | ||||||
|---|---|---|---|---|---|---|---|---|
| PSNR ↑ | SSIM ↑ | LPIPS ↓ | 平均每条光线采样数 | FPS ↑ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | |
| PixelNeRF | 19.31 | 0.789 | 0.382 | 96 | 0.019 | - | - | - |
| IBRNet | 26.04 | 0.917 | 0.191 | 128 | 0.217 | - | - | - |
| MVSNeRF | 26.63 | 0.931 | 0.168 | 128 | 0.416 | 24.03 | 0.914 | 0.192 |
| ENERF | 27.61 | 0.957 | 0.089 | 2 | 19.5 | 25.48 | 0.942 | 0.107 |
| MatchNeRF | 26.91 | 0.934 | 0.159 | 128 | 1.04 | 25.03 | 0.919 | 0.181 |
| GNT | 26.39 | 0.923 | 0.156 | 192 | 0.01 | 24.32 | 0.903 | 0.201 |
| CG-NeRF | 28.21 | 0.930 | 0.170 | 4 | 2.56 | - | - | - |
| MuRF | 28.76 | 0.961 | 0.077 | 80 | 0.934 | 25.61 | 0.938 | 0.104 |
| ConvGLR | 31.65 | 0.952 | 0.080 | 128 | 0.825 | - | - | - |
| MVSGaussian | 28.21 | 0.963 | 0.076 | 1 | 21.5 | 25.78 | 0.947 | 0.095 |
| ENERF+Ours (2×2) | 28.86 | 0.964 | 0.073 | 0.42 | 28.6 | 26.39 | 0.949 | 0.089 |
| ENERF+Ours (4×4) | 28.21 | 0.957 | 0.088 | 0.10 | 43.6 | 26.09 | 0.942 | 0.105 |
| MVSGaussian+Ours | 28.40 | 0.962 | 0.076 | 1 | 23.4 | 26.16 | 0.946 | 0.093 |
| 方法 | 设置 | Real Forward-facing | NeRF Synthetic | ||||
|---|---|---|---|---|---|---|---|
| PSNR ↑ | SSIM ↑ | LPIPS ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | ||
| PixelNeRF | 3视角 | 11.24 | 0.486 | 0.786 | 7.39 | 0.658 | 0.411 |
| IBRNet | 21.79 | 0.671 | 0.279 | 22.44 | 0.874 | 0.195 | |
| MVSNeRF | 21.93 | 0.795 | 0.252 | 23.62 | 0.897 | 0.176 | |
| ENERF | 23.63 | 0.843 | 0.182 | 26.17 | 0.943 | 0.085 | |
| MatchNeRF | 22.43 | 0.805 | 0.244 | 23.20 | 0.897 | 0.164 | |
| GNT | 22.98 | 0.761 | 0.221 | 25.80 | 0.905 | 0.104 | |
| CG-NeRF | 23.93 | 0.820 | 0.210 | 25.01 | 0.900 | 0.190 | |
| MuRF | 23.70 | 0.860 | 0.181 | 24.37 | 0.885 | 0.117 | |
| MVSGaussian | 24.07 | 0.857 | 0.164 | 26.46 | 0.948 | 0.071 | |
| ENERF+Ours (2×2) | 24.33 | 0.860 | 0.162 | 26.49 | 0.948 | 0.075 | |
| ENERF+Ours (4×4) | 23.84 | 0.851 | 0.174 | 26.00 | 0.943 | 0.083 | |
| MVSGaussian+Ours | 24.15 | 0.858 | 0.165 | 26.48 | 0.947 | 0.070 | |
| MVSNeRF | 2视角 | 20.22 | 0.763 | 0.287 | 20.56 | 0.856 | 0.243 |
| ENERF | 22.78 | 0.821 | 0.191 | 24.83 | 0.931 | 0.117 | |
| MatchNeRF | 20.59 | 0.775 | 0.276 | 20.57 | 0.864 | 0.200 | |
| GNT | 20.91 | 0.683 | 0.293 | 23.47 | 0.877 | 0.151 | |
| MuRF | 22.55 | 0.820 | 0.218 | 22.96 | 0.866 | 0.137 | |
| MVSGaussian | 23.11 | 0.834 | 0.175 | 25.06 | 0.937 | 0.079 | |
| ENERF+Ours (2×2) | 23.06 | 0.824 | 0.186 | 25.01 | 0.937 | 0.087 | |
| ENERF+Ours (4×4) | 23.06 | 0.826 | 0.187 | 24.65 | 0.932 | 0.098 | |
| MVSGaussian+Ours | 23.13 | 0.834 | 0.175 | 25.10 | 0.937 | 0.079 | |
这些数据显示了在应用我们的方法后,ENeRF在PSNR和FPS指标上均有所改善。从定性结果(如下图所示)来看,我们的方法生成的图像在细节表现和伪影抑制方面,与一些现有方法相比也展现了有竞争力的效果。

图3 定性结果比较
总结与展望
本研究提出了一种深度引导的束采样策略,旨在提升可泛化神经辐射场的渲染效率和图像质量。实验结果表明,该方法在多个基准数据集上取得了一定的积极效果。通过对相邻光线进行分组处理并结合深度信息进行自适应采样,我们的方法为减少计算冗余提供了一个可行的思路。
我们认为这项工作是对现有可泛化新视角合成技术的一个补充。未来的研究方向可能包括探索更优的束定义方式、更高效的特征聚合机制,以及将此策略应用于更广泛的三维视觉任务中。我们希望这项研究能为相关领域的研究者提供一些有益的参考。
感谢您的阅读。相关论文和代码已公开,欢迎查阅和交流。