本文介绍实验室团队在CVPR 2025上发表的一项工作,该工作仅需1-3张图即可实现高质量新视角合成。
论文标题:GoLF-NRT: Integrating Global Context and Local Geometry for Few-Shot View Synthesis
现有方法的痛点:只见树木,不见森林
近年来,神经辐射场(NeRF)在新视角合成领域取得了显著进展,能够生成非常逼真的图像 。但是,传统的NeRF方法通常需要针对每个场景进行优化,并且需要大量的输入图片 。为了解决这个问题,研究者们提出了可泛化NeRF模型,它们可以学习场景的先验知识,从而推广到未知的场景 。
这些方法在数据充足时表现尚可,但一旦输入视角骤减,就容易因为遮挡、反射或特征稀疏而“迷失方向”,容易产生模糊或伪影 。有些工作尝试引入语义等辅助信息,但在低于3个视角时,这些信息本身的模糊性反而可能加剧问题 。究其原因,它们往往过于依赖局部线索,缺乏对场景全局上下文的理解。
我们的答案:GoLF-NRT —— 全局与局部“双剑合璧”

图1 全局特征与局部特征对比
为了解决少样本视角合成的难题,我们提出了GoLF-NRT (Global and Local feature Fusion-based Neural Rendering Transformer) 。顾名思义,我们的核心思想就是将全局场景上下文(Global Context)和局部几何特征(Local Geometry)进行有效融合,让模型既能“纵览全局”,又能“明察秋毫”。
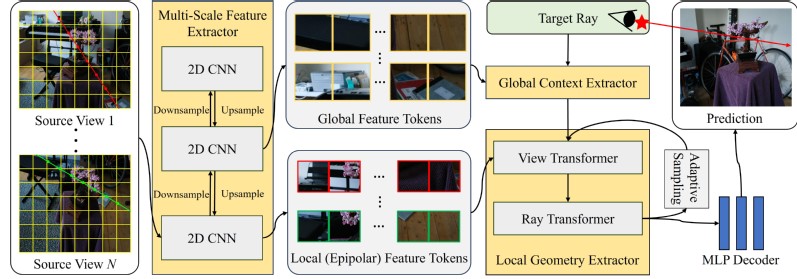
图2 GoLF-NRT网络架构概述
GoLF-NRT的核心组件:
全局上下文特征提取模块:
这个模块的目标是建立对整个场景的整体理解 。
我们使用了一个3D Transformer结构来处理从各个源视图提取的特征。考虑到直接在多视图图像上应用Transformer计算量很大,我们采用了稀疏注意力机制(包括块内注意力、网格内注意力和视图间注意力),这大大降低了计算成本,使其变得可行。
该模块能生成一个强大的场景表征,并为每一条目标光线解码出专属的全局上下文特征。这就像给模型装上了一个“广角镜”,即使输入信息有限,也能把握场景的关键属性。
局部几何特征提取模块:
这个模块专注于挖掘精细的几何信息。我们基于GNT的框架,沿外极线聚合特征 。
全局上下文引导聚合:我们将全局上下文特征作为查询(Query)输入到视图Transformer中。这利用了全局信息来帮助模型更好地判断不同源视图的贡献,尤其是在处理遮挡和视角稀疏等困难情况时,能得到更准确的局部几何特征。
基于核回归的自适应采样:为了更有效地在光线上采样点,我们利用光线Transformer中的注意力权重作为指导。但直接使用注意力权重可能导致采样点分布不佳。因此,我们引入了核回归(Kernel Regression)方法,将这些权重转换成一个平滑、正则化的概率密度函数(PDF)。这样,我们就可以根据这个PDF进行采样,将更多的采样点集中在物体表面附近,从而更准确地感知几何形状。
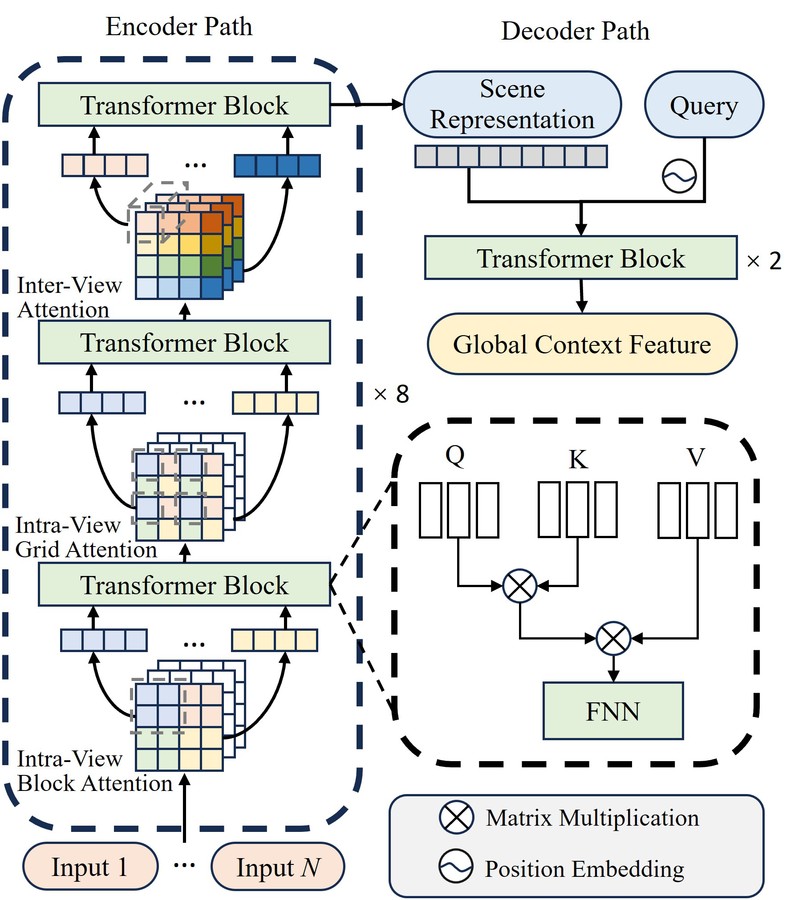
图3 全局上下文特征提取模块网络架构
最后,我们将全局特征和局部特征融合起来 ,并通过一个MLP解码器预测出目标光线的颜色。
实验结果
我们在LLFF、Blender和Shiny等标准数据集上进行了测试。
少样本结果(1-3视角):如表1所示,与现有的多种方法相比,GoLF-NRT在输入视角为1、2或3张的情况下,在PSNR、SSIM和LPIPS指标上都取得了领先或具有竞争力的结果 。特别是在LLFF数据集和3视角输入下,我们的方法在PSNR上比之前的SOTA方法CaesarNeRF提升了0.75 dB。
多样本结果(10视角):如表2所示,即使在输入视角增加到10张时,我们的方法依然表现出色,证明了其良好的适应性。
定性比较:从图4和图5的视觉效果来看,我们的方法能够生成更清晰、伪影更少的图像,尤其是在处理复杂纹理和边界区域时,效果优于GNT、EVE-NeRF、CaesarNeRF等方法。
同时使用全局和局部特征比只使用局部特征效果更好,PSNR提升了0.44 dB。
使用全局特征作为查询能进一步提升性能。
自适应采样和核回归策略对于提升几何感知和最终渲染质量非常重要。
表1:少样本(1-3输入视图)结果定量比较
| Input | Methods | LLFF | Blender | Shiny | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | LPIPS↓ | PSNR↑ | SSIM↑ | LPIPS↓ | PSNR↑ | SSIM↑ | LPIPS↓ | ||
| 3-view | IBRNet | 23.00 | 0.752 | 0.262 | 22.44 | 0.874 | 0.195 | 21.96 | 0.710 | 0.281 |
| MVSNeRF | 19.84 | 0.729 | 0.314 | 23.62 | 0.897 | 0.176 | 18.55 | 0.645 | 0.343 | |
| MatchNeRF | 22.30 | 0.731 | 0.234 | 23.20 | 0.897 | 0.164 | 20.77 | 0.672 | 0.249 | |
| MVSGaussian | 24.07 | 0.857 | 0.164 | 25.54 | 0.944 | 0.073 | 20.49 | 0.661 | 0.254 | |
| GNT | 23.28 | 0.768 | 0.230 | 25.80 | 0.905 | 0.104 | 22.47 | 0.720 | 0.247 | |
| EVE-NeRF | 22.79 | 0.754 | 0.226 | 23.43 | 0.903 | 0.132 | 24.11 | 0.781 | 0.204 | |
| CaesarNeRF | 23.45 | 0.794 | 0.176 | 23.56 | 0.908 | 0.131 | 22.74 | 0.723 | 0.241 | |
| GoLF-NRT | 24.20 | 0.821 | 0.148 | 24.30 | 0.916 | 0.097 | 25.06 | 0.765 | 0.207 | |
| 2-view | MVSNeRF | 19.15 | 0.704 | 0.336 | 20.56 | 0.856 | 0.243 | 17.25 | 0.577 | 0.416 |
| MatchNeRF | 21.08 | 0.689 | 0.272 | 20.57 | 0.864 | 0.200 | 20.28 | 0.636 | 0.278 | |
| pixelSplat | 22.99 | 0.810 | 0.190 | 15.77 | 0.755 | 0.314 | 20.42 | 0.617 | 0.327 | |
| GNT | 20.94 | 0.687 | 0.301 | 23.47 | 0.877 | 0.151 | - | - | - | |
| EVE-NeRF | 19.95 | 0.607 | 0.340 | 21.62 | 0.867 | 0.180 | 20.89 | 0.667 | 0.321 | |
| CaesarNeRF | 21.94 | 0.736 | 0.224 | 22.07 | 0.879 | 0.176 | 21.47 | 0.652 | 0.293 | |
| GoLF-NRT | 22.48 | 0.765 | 0.193 | 22.34 | 0.886 | 0.143 | 23.03 | 0.692 | 0.261 | |
| 1-view | GNT | 16.60 | 0.491 | 0.514 | 15.53 | 0.634 | 0.371 | 15.99 | 0.400 | 0.548 |
| CaesarNeRF | 18.31 | 0.521 | 0.435 | 15.76 | 0.698 | 0.366 | 17.57 | 0.472 | 0.467 | |
| GoLF-NRT | 18.31 | 0.527 | 0.410 | 16.34 | 0.706 | 0.309 | 18.96 | 0.513 | 0.393 | |
表2:多样本(10输入视图)结果定量比较
| Methods | LLFF | Blender | Shiny | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | LPIPS↓ | PSNR↑ | SSIM↑ | LPIPS↓ | PSNR↑ | SSIM↑ | LPIPS↓ | |
| PixelNeRF | 18.66 | 0.588 | 0.463 | 22.65 | 0.808 | 0.202 | - | - | - |
| IBRNet | 25.17 | 0.813 | 0.200 | 26.73 | 0.908 | 0.101 | 23.60 | 0.785 | 0.180 |
| NeuRay | 25.35 | 0.818 | 0.198 | 26.48 | 0.944 | 0.091 | 25.72 | 0.880 | 0.175 |
| GPNR | 25.72 | 0.880 | 0.175 | 28.29 | 0.927 | 0.080 | 24.12 | 0.860 | 0.170 |
| GNT | 25.53 | 0.836 | 0.178 | 26.01 | 0.925 | 0.088 | 26.56 | 0.852 | 0.132 |
| CaesarNeRF | 25.16 | 0.851 | 0.138 | 26.75 | 0.915 | 0.083 | 26.66 | 0.849 | 0.146 |
| EVE-NeRF | 27.16 | 0.869 | 0.141 | 27.03 | 0.952 | 0.072 | 27.41 | 0.883 | 0.113 |
| GOLF-NRT | 26.42 | 0.879 | 0.109 | 29.74 | 0.963 | 0.060 | 28.01 | 0.885 | 0.112 |

图4 少样本(1-3输入视图)结果定性比较

图5 多样本(10输入视图)结果定性比较
消融学习
我们通过消融实验验证了模型各个组成部分的有效性(如表 3 所示)。实验结果表明:
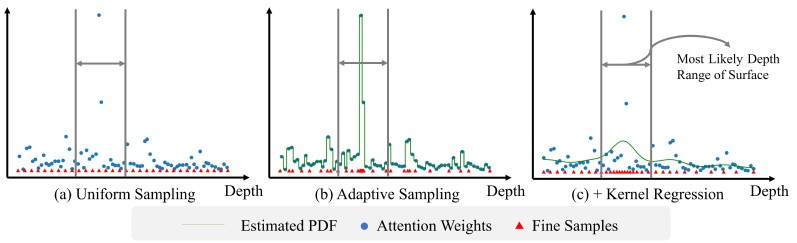
图6 基于核回归的自适应采样
总结
我们提出了GoLF-NRT,一种结合全局上下文和局部几何特征的神经渲染Transformer模型。通过使用高效的稀疏3D Transformer和基于核回归的自适应采样策略,我们的方法能够在输入视角极少的情况下,显著提升新视角合成的质量,并取得了SOTA性能。我们希望这项工作能有助于推动NeRF技术在数据有限的实际应用中的发展 。
感谢您的阅读。相关论文和代码已公开,欢迎查阅和交流。